Auto-Inject Prompt Caching Checkpoints
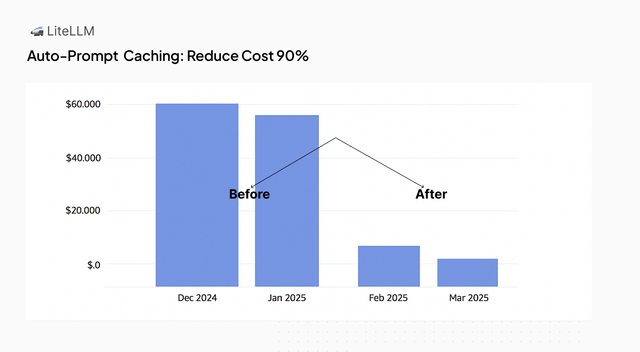
Reduce costs by up to 90% by using LiteLLM to auto-inject prompt caching checkpoints.
How it works
LiteLLM can automatically inject prompt caching checkpoints into your requests to LLM providers. This allows:
- Cost Reduction: Long, static parts of your prompts can be cached to avoid repeated processing
- No need to modify your application code: You can configure the auto-caching behavior in the LiteLLM UI or in the
litellm config.yamlfile.
Configuration
You need to specify cache_control_injection_points in your model configuration. This tells LiteLLM:
- Where to add the caching directive (
location) - Which message to target (
role)
LiteLLM will then automatically add a cache_control directive to the specified messages in your requests:
"cache_control": {
"type": "ephemeral"
}
LiteLLM Python SDK Usage
Use the cache_control_injection_points parameter in your completion calls to automatically inject caching directives.
Basic Example - Cache System Messages
from litellm import completion
import os
os.environ["ANTHROPIC_API_KEY"] = ""
response = completion(
model="anthropic/claude-3-5-sonnet-20240620",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant tasked with analyzing legal documents.",
},
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 400,
},
],
},
{
"role": "user",
"content": "what are the key terms and conditions in this agreement?",
},
],
# Auto-inject cache control to system messages
cache_control_injection_points=[
{
"location": "message",
"role": "system",
}
],
)
print(response.usage)
Key Points:
- Use
cache_control_injection_pointsparameter to specify where to inject caching location: "message"targets messages in the conversationrole: "system"targets all system messages- LiteLLM automatically adds
cache_controlto the last content block of matching messages (per Anthropic's API specification)
LiteLLM's Modified Request:
LiteLLM automatically transforms your request by adding cache_control to the last content block of the system message:
{
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant tasked with analyzing legal documents."
},
{
"type": "text",
"text": "Here is the full text of a complex legal agreement...",
"cache_control": {"type": "ephemeral"} // Added by LiteLLM
}
]
},
{
"role": "user",
"content": "what are the key terms and conditions in this agreement?"
}
]
}
Target Specific Messages by Index
You can target specific messages by their index in the messages array. Use negative indices to target from the end.
from litellm import completion
import os
os.environ["ANTHROPIC_API_KEY"] = ""
response = completion(
model="anthropic/claude-3-5-sonnet-20240620",
messages=[
{
"role": "user",
"content": "First message",
},
{
"role": "assistant",
"content": "Response to first",
},
{
"role": "user",
"content": [
{"type": "text", "text": "Here is a long document to analyze:"},
{"type": "text", "text": "Document content..." * 500},
],
},
],
# Target the last message (index -1)
cache_control_injection_points=[
{
"location": "message",
"index": -1, # -1 targets the last message, -2 would target second-to-last, etc.
}
],
)
print(response.usage)
Important Notes:
- When a message has multiple content blocks (like images or multiple text blocks),
cache_controlis only added to the last content block - This follows Anthropic's API specification which requires: "When using multiple content blocks, only the last content block can have cache_control"
- Anthropic has a maximum of 4 blocks with
cache_controlper request
LiteLLM's Modified Request:
LiteLLM adds cache_control to the last content block of the targeted message (index -1 = last message):
{
"messages": [
{
"role": "user",
"content": "First message"
},
{
"role": "assistant",
"content": "Response to first"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Here is a long document to analyze:"
},
{
"type": "text",
"text": "Document content...",
"cache_control": {"type": "ephemeral"} // Added by LiteLLM to last content block only
}
]
}
]
}
LiteLLM Proxy Usage
You can configure cache control injection in the proxy configuration file.
- litellm config.yaml
- LiteLLM UI
model_list:
- model_name: anthropic-auto-inject-cache-system-message
litellm_params:
model: anthropic/claude-3-5-sonnet-20240620
api_key: os.environ/ANTHROPIC_API_KEY
cache_control_injection_points:
- location: message
role: system
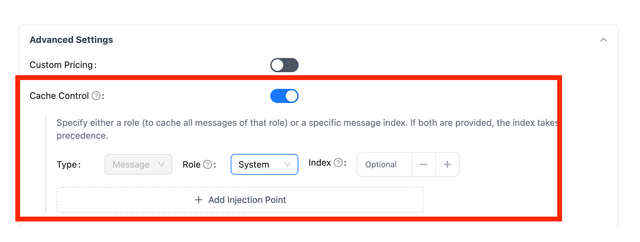
On the LiteLLM UI, you can specify the cache_control_injection_points in the Advanced Settings tab when adding a model.
Detailed Example
1. Original Request to LiteLLM
In this example, we have a very long, static system message and a varying user message. It's efficient to cache the system message since it rarely changes.
{
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant. This is a set of very long instructions that you will follow. Here is a legal document that you will use to answer the user's question."
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the main topic of this legal document?"
}
]
}
]
}
2. LiteLLM's Modified Request
LiteLLM auto-injects the caching directive into the system message based on our configuration:
{
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant. This is a set of very long instructions that you will follow. Here is a legal document that you will use to answer the user's question.",
"cache_control": {"type": "ephemeral"}
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the main topic of this legal document?"
}
]
}
]
}
When the model provider processes this request, it will recognize the caching directive and only process the system message once, caching it for subsequent requests.
Related Documentation
- Manual Prompt Caching - Learn how to manually add
cache_controldirectives to your messages